https://github.com/googlefonts/noto-cjk/tree/main/Sans/OTF/SimplifiedChinese
When testing with this specific font with Chinese characters attempting include the zero width space / insert it between Chinese characters does not seem to work.

Test string
页哨临蛤扩杯桃波楚淡啜遣帝虐能嚷在惨挑茉整精
Zero Width Space
U+200B
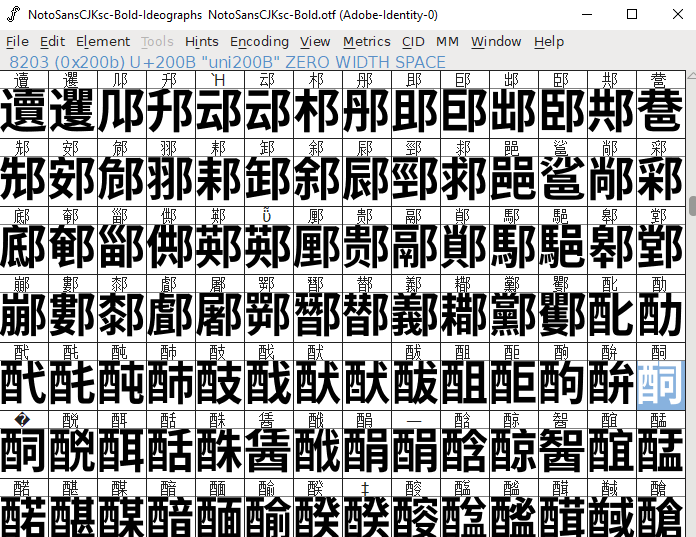
FontForge claims there’s a character there but seems weird to me. 
The other test font I was using seems to look more correct to me.
There must be something I don’t understand in relation to Simplified Chinese fonts with zero width space.
I tried using this https://github.com/akiirui/RobotoCJKSC to test if it was an OTF issue somehow and it has the ZWS space listed as I’d expect at least but still shows ~ in engine when attempting to add the ZWS character between Chinese characters.
I tested just trying to have multiple ZWS characters together and it displays nothing.
With more testing, I think it’s not an issue with the fonts but just somehow the UTF8 stuff.
When I try to include just “\226\128\139” in the extra characters this happens to the raw file:
font: "/assets/fonts/babamoji1004/BABAmoji.ttf"
material: "/builtins/fonts/label-df.material"
size: 15
antialias: 1
alpha: 1.0
outline_alpha: 0.0
outline_width: 0.0
shadow_alpha: 0.0
shadow_blur: 0
shadow_x: 0.0
shadow_y: 0.0
extra_characters: "\357\277\275\n"
"8\v9"
output_format: TYPE_DISTANCE_FIELD
all_chars: false
cache_width: 0
cache_height: 0
render_mode: MODE_SINGLE_LAYER
It’s something the editor is doine changing the extra_characters field. I tried setting it to \xe2\x80\x8b and the editor changed it to extra_characters: “\342\200\213”
And now it seems to be working right, (but only with the modified ttf not the otf) and with the \342\200\213 listed in the extra chars raw text (I don’t understand this, I guess they are Octal UTF-8 bytes).

Something to be aware of is you cannot use the same fonts for Simplified Chinese and Traditional Chinese texts. They have their own set of glyphs.