Pure immutability would make it impossible to write loops, which I find silly (recursion is used, but because of this I hated Erlang).
Immutability is imho kind of a defensive programming. During development it might help you spot issues in your code, when you want to “hack” your program, by modifying your state (of object, data, table, any structure) in an unsuitable place. Your architecture modify data anyway. But in DOP, instead of modifying data, you are switching reference to a new modified data, a new instance.
o solve issue with deep copying whole data it is proposed to use powerful “structural sharing”:
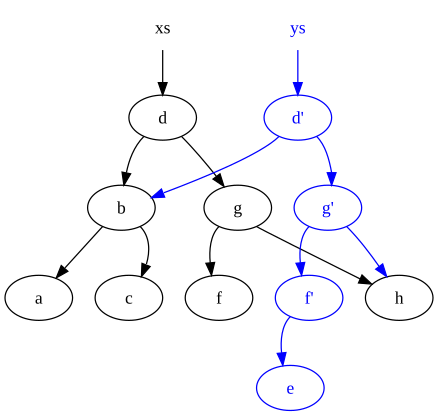
- Persistent data structure - Wikipedia
- Structural sharing with 7 lines of JavaScript. | Yehonathan Sharvit
You might not notice it, but DOP describes… Git.
All the features introduced in Git are very well suiting DOP - you don’t change the data, you just make a snapshot of changes and join it with the rest of data that was unchanged (structural sharing), then you “commit” your changes, by changing a reference to your newest data state. This is were DOP shines and really serves the purpose. Other useful thing are distributed systems, microservices, or in parallelisation, where relying on immutable data and system state updates can perform really well.
Lua also tought me how Composition_over_inheritance is so great ![]()
This is a very good approach (like the one I used in this Tic Tac Toe example). It should always be separated. I made many, many prototypes were it wasn’t. It’s just the answer to “Why it’s so hard to finish a game?” or anything ![]()
Almost all architectures or applications, especially GUI heavy, revolve around such idea (MVC, MVVM) and I used them in software development job - why not using it in games too?
I remember (it was probably maybe even me) a question about good architecture in games and I was looking for such an answer for a long time, checking out different approaches, always receiving an answer that “it depends” and I couldn’t agree with it just like that. I was looking for a sweet spot, only to come to a conclusion that really “it depends”… I made a circle, but gained a baggage of knowledge along the way, that’s why this meme template is so relatable ![]()
BUT
when you’re doing any software that is larger than Tic Tac Toe, a good architecture is a solid foundation for making your life easier. Of course, it might need refactoring along the way to make it always fresh, but when the foundation is solid, you can build a higher tower more easily.
I find this set of rules really good for progammers:
It’s indeed a tough task. I’m right now studying @Insality’s Shooting Circles and all the very cool stuff he made, that I always wished to do, but never finished (like tiny-ecs project I started around 3 years ago and is still only on my local drive), and even though the documentation and example is amazing and I don’t think it can be done any better tbh, there is a lot of ![]() put in here and with Panthera and Detiled it looks like a perfect solution, it has a very high entry level to get in, but I believe it will be beneficial to learn, because it surely can speed up development a ton!
put in here and with Panthera and Detiled it looks like a perfect solution, it has a very high entry level to get in, but I believe it will be beneficial to learn, because it surely can speed up development a ton!