I’m really under vast impression of book “Data Oriented Programming” by Yehonathan Sharvit (a lot from it is available online, e.g. What is Data Oriented Programming? | Yehonathan Sharvit, but I also recommend full book) which gathers all the data related approaches (that are existing here since LISP) into one set of 4 rules:
- Separate data from functionalities (behavior)
- Representing data with generic structures
- Treating data as immutable
- Separating data schema from data representation (so dynamic typing with optional runtime checks, e.g. with JSON schema, but I use Lua table here simply)
This differs from DOD which focuses on cache misses and general performance, when thinking about data first, but data in memory. DOP on the other hand focuses on data as abstraction and on designing proper architectures basing on them. It’s language agnostic and paradigm agnostic, so can be applied (or broken) in FP or OOP.
Rules #1 is undoubtly good imho, I do it anyway as much as possibile, because I spent my whole life writing OOP and find stateful classes bugprone as hell.
Because of this rule #2 feels also good, because you can then reuse a lot of code that works with all the data (but there is a cost to it - data validation, that is addressed by rule #4)
Point number 3 is most controversial, because not all languages support it natively (but more and more do), but it can be achieved even in Lua (I made a Lua module for this, testing it and will soon open source it).
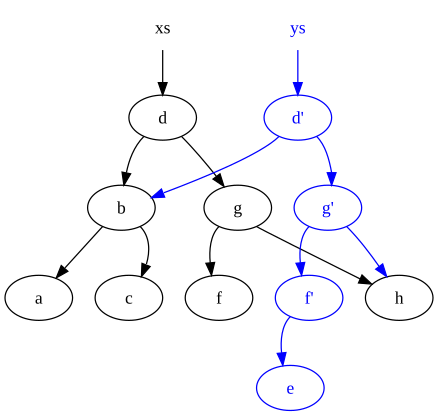
But beside such a set of rules looks very beneficial, especially for bigger architectures and data heavy games. You can store only one set of immutable data (think of it like “version”) or multiple of them (and traverse back in time, if you wish). You don’t change the data, but you create new version of data and “commit” it - the name is purposeful - imho GIT perfectly follows DOP rules and is a great example on how to think about data in DOP way. You also don’t need to mąkę copies of ALL your data only to change one field, e.g. updated player’s position or some single item in inventory - you can use something like structural sharing to only change affected data and reference to the data from previous version for the rest (those field can also reference to previous versions, etc.)
I’m testing full DOP approach for one project (in Defold, in Lua), so I can tell more after it, but so far, I’m very pleased.
Ah, and finally - ECS is one of the Architecture that perfectly fits DOP, that’s why I come up with it here. I would say it’s one of the DOP implementations that was vastly adopted in gamedev, especially for similar objects clones (aka enemies)-heavy games.
And Clojure is definitely the best for DOP, but since I still can’t come to an agreement with FP I can’t tell if Defold Editor is using approach that benefis of those rules ( and can’t tell if the graph based implementation is).